
LODы, порядок операций и как работает Табло
Статья подготовлена в рамках сериала «Залетай в BI»
На прошлой недели Руслан прокачивал навыки работы со сложным техническим функционалом. Для того чтобы прокачать работу с расчётами я дал задачки, где нужно было построить одни и те же графики при помощи табличных вычислений и LODов. Тут были две основные проблемы: переусложненные вычисления и ошибки в понимании как работает порядок операций. Разберём две эти проблемы на небольших примерах на любимом Sample Superstore.
Как работают LODы и Табло в целом
Предположим, что хотим посчитать для каждого штата процент продаж от общего с помощью LODа (понятно, что для этого лучше подошли бы тейбл кальки, это чисто учебная задача). Руслан сделал это с помощью такой формулы:
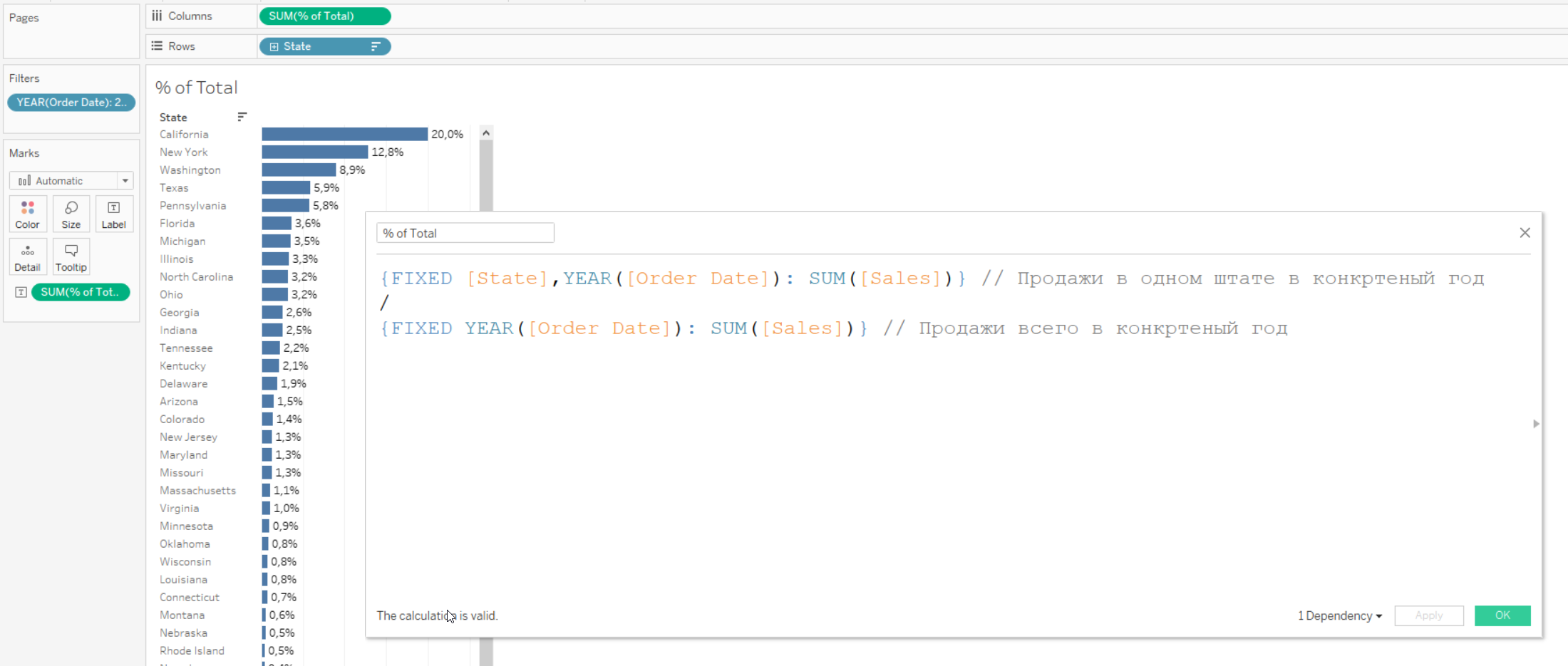
И в целом это работает верно, но это слишком сложно — мы используем целых два LODа вместо одного. Как же понять, что формула в числителе лишняя?
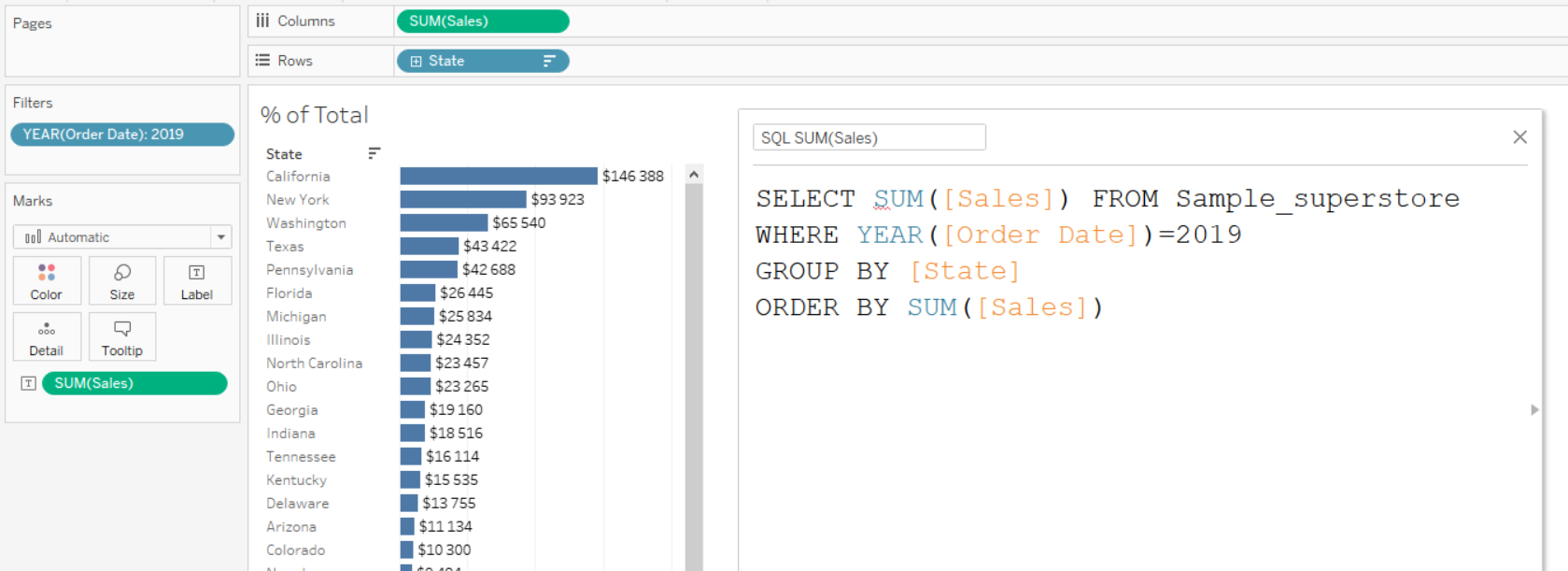
Во первых давай разберёмся какой SQL запрос послало Табло, когда мы просто собрали лист с суммой продаж по штатам. Когда мы кладём любые пилюли на полку Табло формирует запрос к базе данныых, получает в ответ агрегированную таблицу данных и визуализирует её. Если мы положили пилюли как на скрине, то Табло отправило примерно такой запрос (не ругайте меня за нотацию, у меня лапки на счёт SQL, сейчас важнее смысл). Это, кстати, называется VIZQL — проприетарная технология Табло превращения пилюль в запросы к БД.
Теперь давайте разберёмся как работает LOD (в данном случае FIXED). Level of Detail расчет, это такой расчёт, который создаёт отдельный подзапрос к базе данных и потом джойнит его к той агрегированной таблице, которая получилась в результате запроса от VIZQL листа. То есть этот запрос выполняется паралельно основному и потом происходит его джоин. Из-за этого LODы так медленно и работают на больших объёмах данных.
Структура выражения LOD при этом выглядит так:
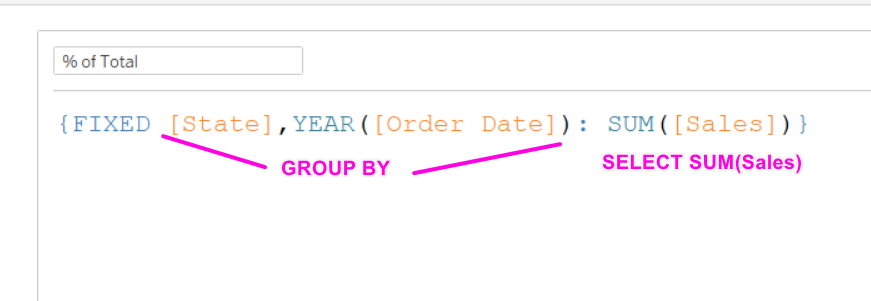
Получается, что наша формула для расчета процента от общего превратиться в такие подзапросы:
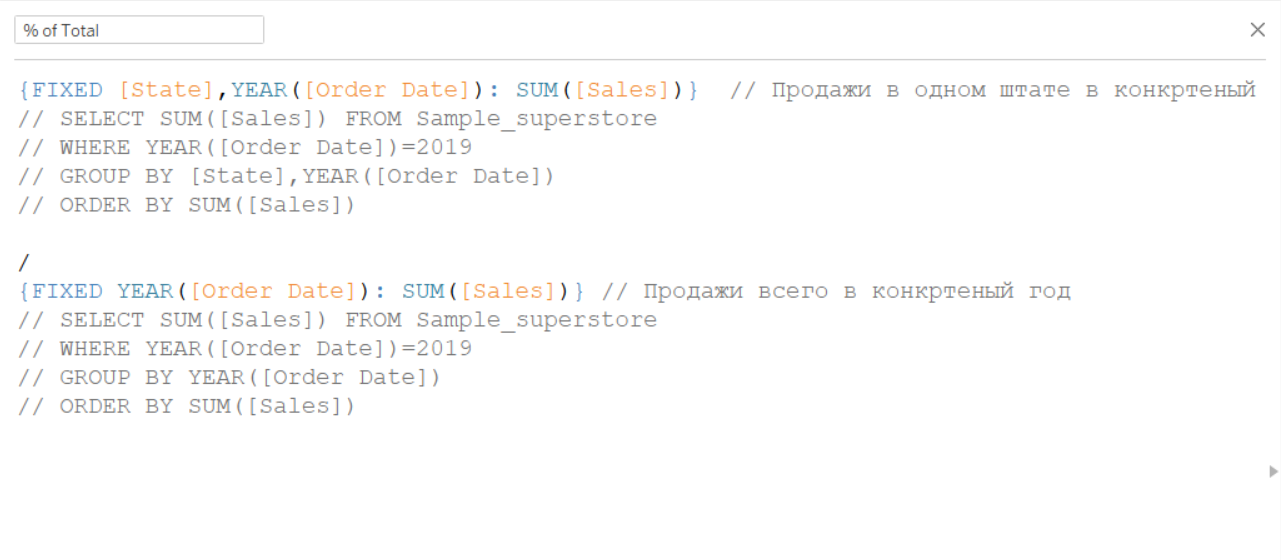
Мы сразу видим, что первый подзапрос, по-сути идентичен тому запросу, что формирует сам лист без применения LOD. В этом случае получается, что мы переусложняем и вместо LOD мы можем использовать в числителе просто SUM([Sales]). Но при этом Табло будет ругаться на то, что мы смешиваем агрегированные и неагрегированные показатели:
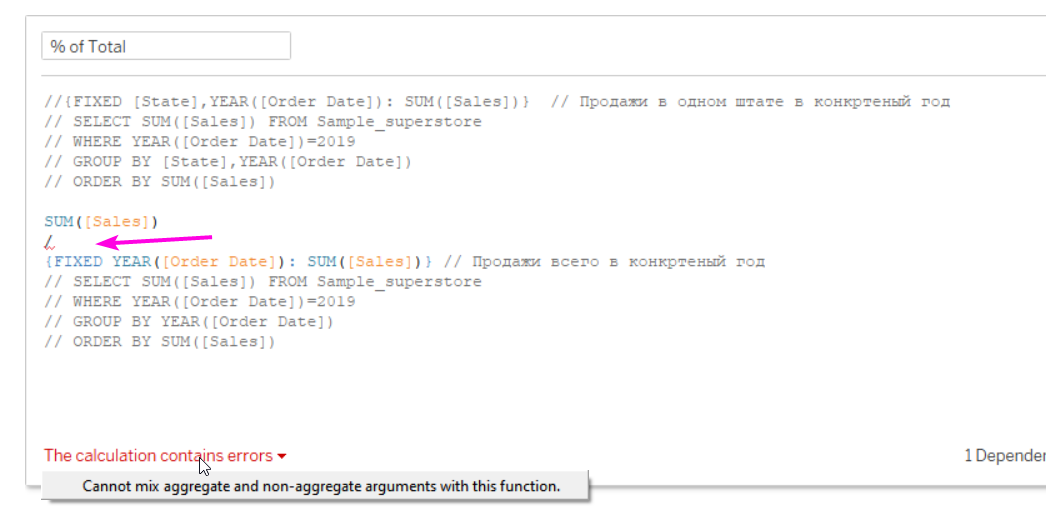
Чтобы избавиться от этой ошибки нам нужно обернуть формулу в знаменателе в агрегацию. Например в сумму. Всё отлично работает.
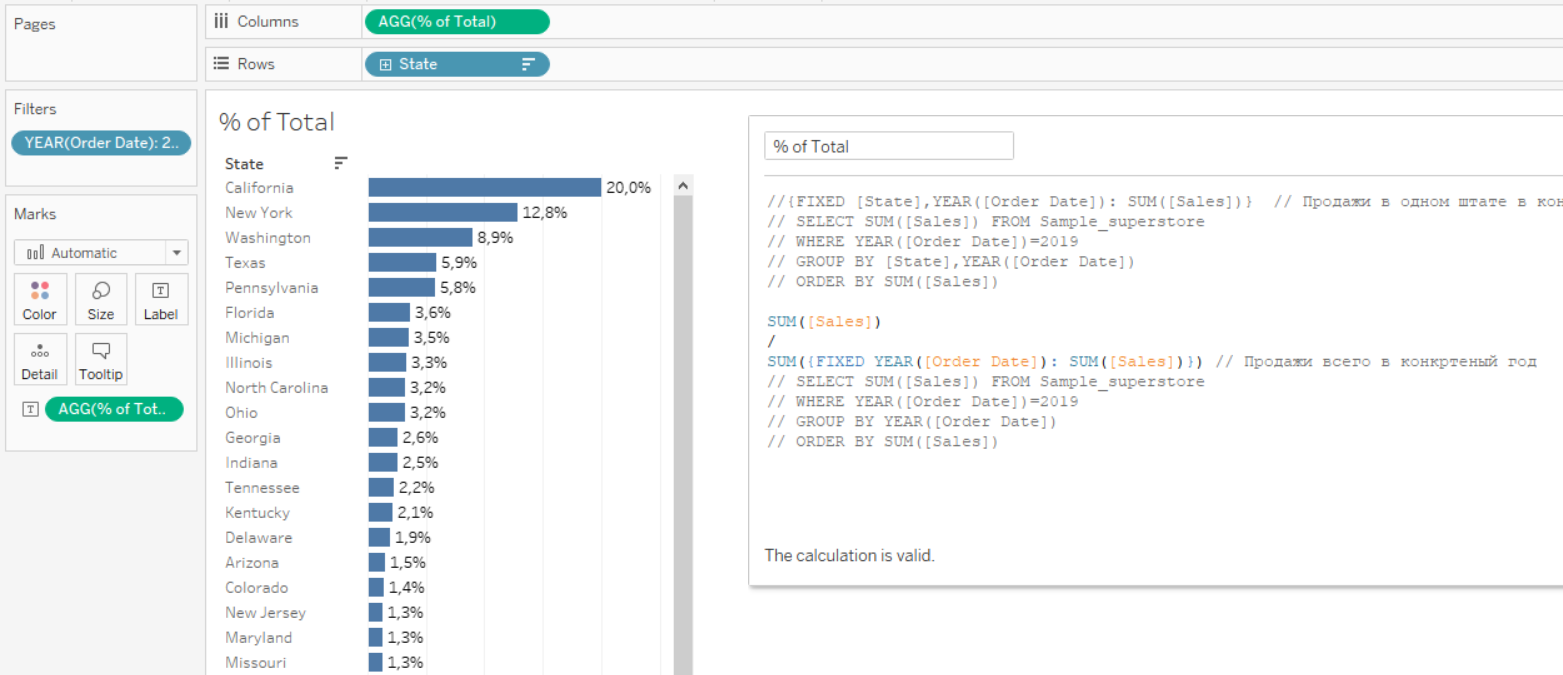
Итого — проверяя свои расчёты, думайте о том, какие агрегаты вы уже получаете из данных, когда используете пилюли. Вам не нужно использовать LOD с такой же грануляций, а просто можно использовать агрегирующую функцию.
Порядок операций
Порядок операций — важный концепт, который как мне кажется часто переусложняют. В целом его обязательно нужно понимать, чтобы знать как происходит трансформация данных в Табло. Это спасёт вас от ошибок расчета TopN, сетов или поможет оптимизировать книгу, например, с помощью фильтров на стороне источника данных. Однако из практических кейсов когда мы можем управлять и менять порядок операций я выделю три основных:
— Превращение обычного расчета в FIXED, чтобы расчет «игнорировал» фильтры в визуализации
— Превращение обычного фильтра в контекстный, чтобы он начал действовать на FIXED расчёты и расчеты TopN
— Использование Table Calcs фильтров, чтобы отфильтровывать данные из вида, не убирая их из агрегированной таблицы.
Пока объяснял это Руслану, нарисовал такую схемку, вот прям живой скрин, поэтому немного страшненький:

Рассмотрим примеры для каждого из кейсов.
1. Превращение обычного расчета в FIXED
Здесь всё обычно супер очевидно, хотим подсчитать что-то, что будет «игнорировать» фильтры. Игнорировать в кавычках, так как на самом деле этот запрос выполняется параллельно. Бизнесовый пример — хотим при выборе конкретного сегмента товаров в фильтре видеть, какой процент продаж он составляет в регионе:
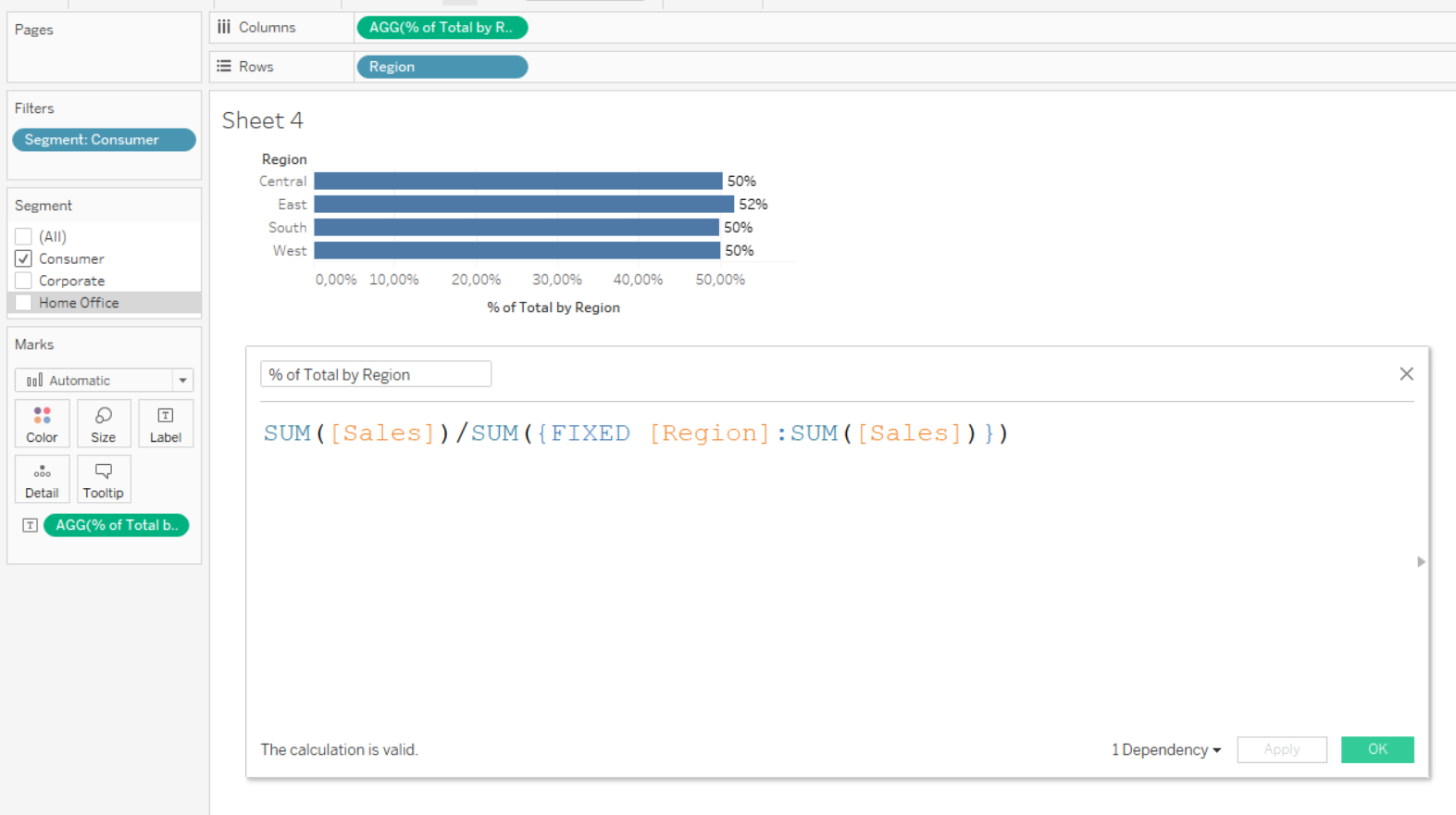
2. Превращение обычного фильтра в контекстный
Превращение фильтра в контекстный позволяет нам применить его «как бы на уровне датасорса». Это на самом деле создаёт временную таблицу к которой уже обращается VIZQL, что может как тормозить, так и иногда ускорять работу Табло. Если вы применяете контекстный фильтр ко всем листам в визуализации, подумайте на счёт его переноса в датасорс фильтры через параметры. Бизнесовый пример — хотим видеть топ-10 штатов по продажам за 2019 год. Используем для этого фильтр TopN, а чтобы он правильно работал при выборе года, фильтр по году заносим в контекст.
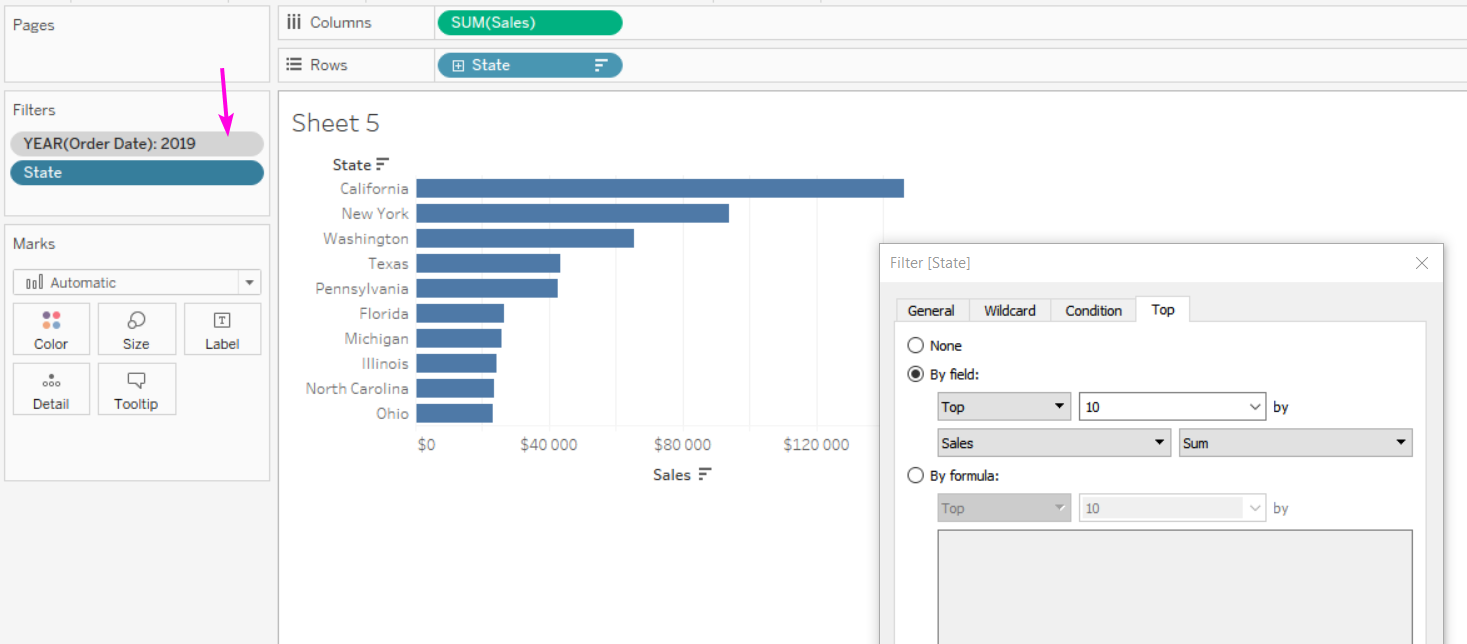
3. Использование Table Calcs фильтров
Чаще всего нужны чтобы работали верно расчеты прироста и функции LOOKUP. Так как если мы фильтруем с помощью дименшен фильтров, то данные отфильтровываются и Табло не почему строить приросты. Бизнесовый пример — хотим показывать текущий год на фоне предыдущего, но при этом хотим скрыть первый год.
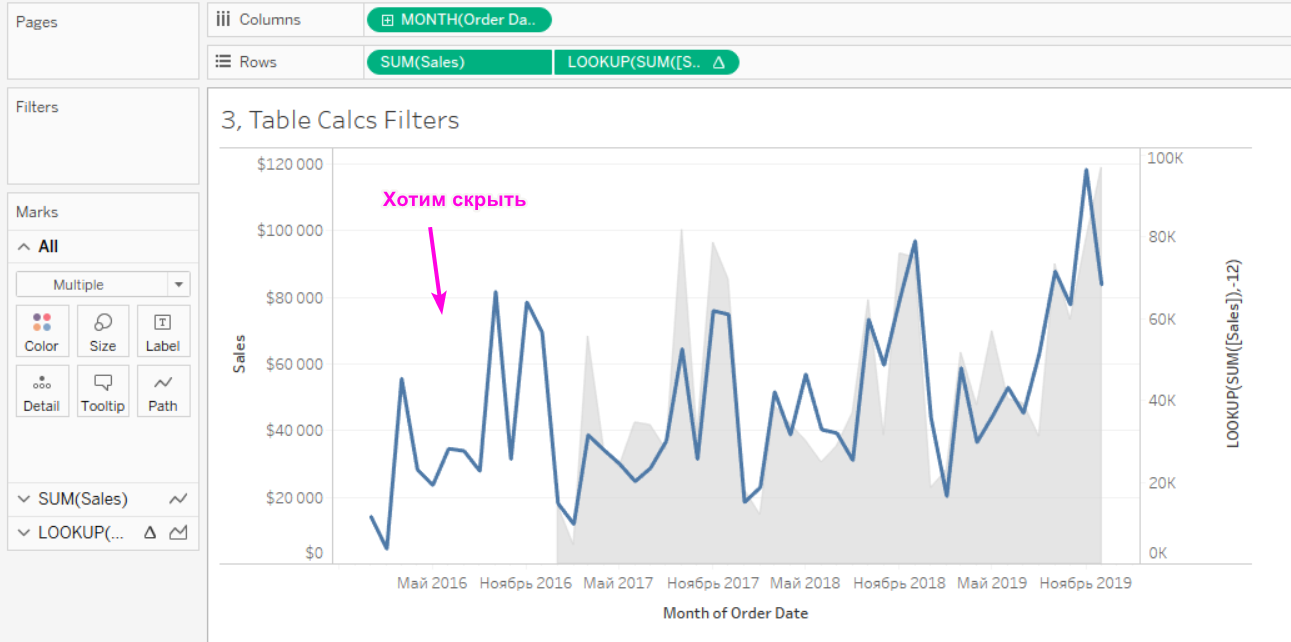
Для этого можно использовать фильтр по FIRST()>-12. Так как это табличный фильтр он и идёт в самом конце фильтрации по порядку операций. Значит он не удалит данные из запроса, а только скроит их из вида, что нам и нужно.
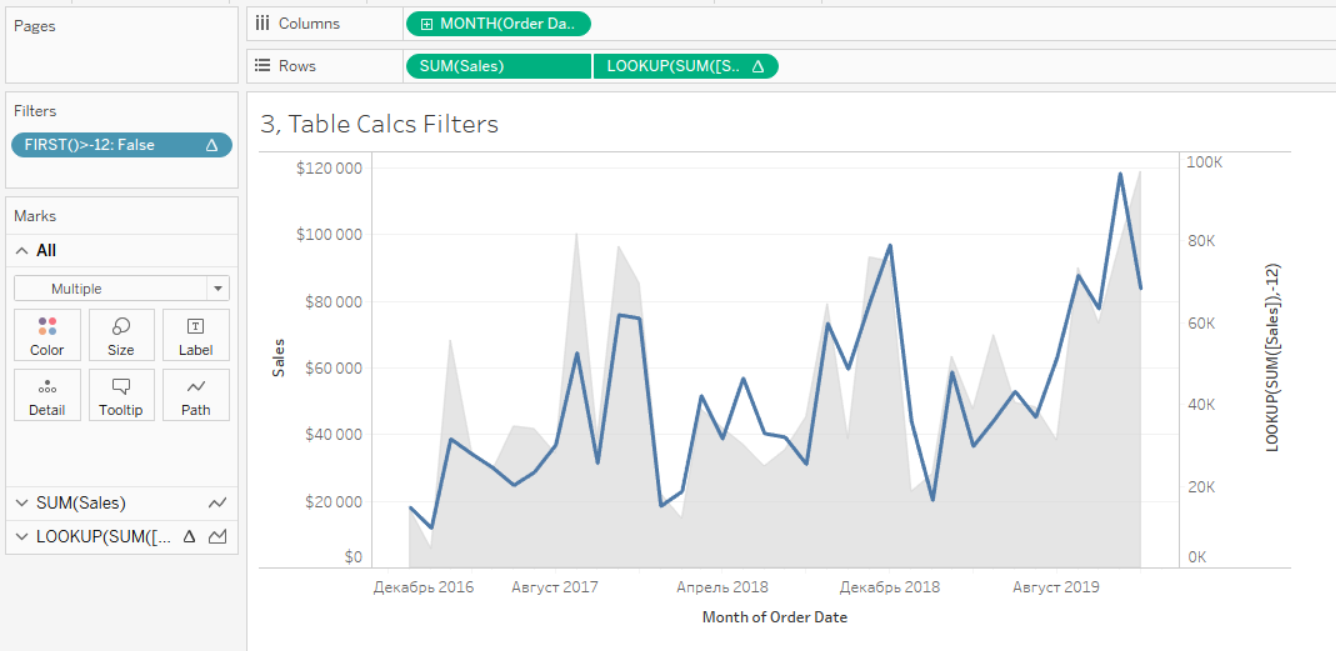
Книга с этими примерами на Паблике.
Понимаю, что привёл примеры без детальных объяснений, но зато кратко и основные кейсы. Есил вам нужно прокачать эту часть поищите в инете по запросу Tableau Order of Operations. Вот, например, неплохое видео.

